This is a really brief follow-up on the earlier local llm performance benchmarking post.
Nvidia RTX 3080
Today I decided to check out also performance of RTX 3080. Now that Windows beta of ollama is available, testing it out was straightforward. As it turns out, it was almost exactly double the speed of Apple Silicon hardware, e.g. llama2:7B model produced around 80 tokens per second, but model load duration was a bit slower (3-4s -> 4,9s).
Groq
The speed is less than 1/10 of Groq is Fast AI Inference, though, so if in a hurry, using something in the cloud seems like the thing. Groq has reasonably good free tier too so I suspect most of my open model stuff will be running there, for the time being.
Currently the free tier limits are following:
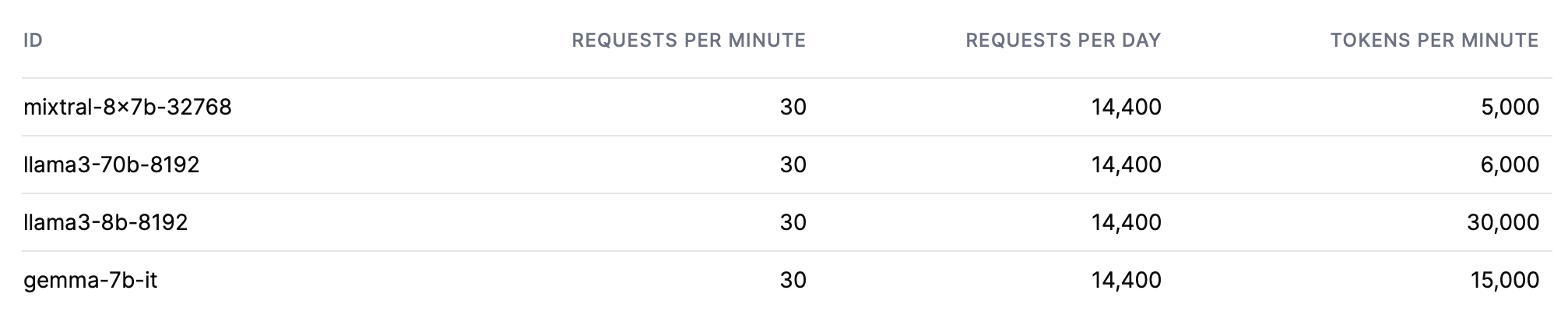 llama3-8b limit is 500 tokens per second, which is more than what all of my hardware at home can produce, for free, for most of the day. This is of course assuming mostly output-driven usage of the tokens (and relatively sane number of requests); I assume the token quota is combined for input and output.
llama3-8b limit is 500 tokens per second, which is more than what all of my hardware at home can produce, for free, for most of the day. This is of course assuming mostly output-driven usage of the tokens (and relatively sane number of requests); I assume the token quota is combined for input and output.